
在线咨询


视频下载


公益讲座


微信咨询

电话咨询



返回顶部





2017年大数据工程师人均年薪20万
大数据
行业分析
大数据
平台搭建
大数据
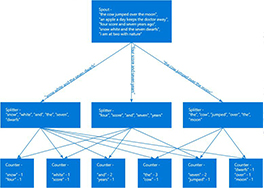
开发应用
大数据
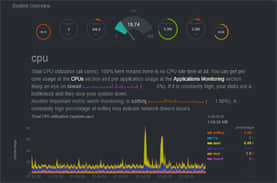
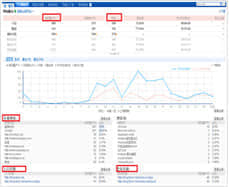
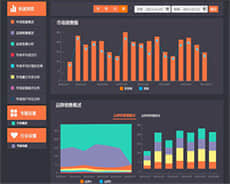
可视化
说明:
1.大数据开发所涉及的数据来源于各种不同种类的数据,需要确定数据的输入及产出、数据量,处理效率、可靠性、可维护性
2.大数据开发过程需要明确大数据项目的目标、基于数据做决定、选择使用权、选择合适的数据输出设备
大数据课程分为13大阶段90大模块课程+6大企业真实项目实战,每个阶段都有实力案例和项目结合,从简单到专业一步一步带领学生
走进大数据开发的世界,帮助学生顺利走上大数据工程师的道路!
 课程
课程■学习内容:JavaSE实战开发
■学习目标:Java面向对象、访问权限、抽象类与接口、
异常处理、I/O流与反射、Java网络编程。
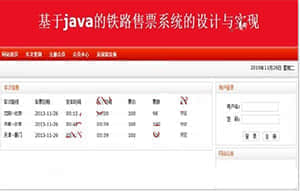
■完成项目:Java多线程模拟多窗口售票,Java集合框架
管理。
 课程
课程■学习内容:JavaEE实战开发
■学习目标:Mysql数据库,JDBC,JavaWeb开发、
Servlet JSP、Java三大框架核心框架开发
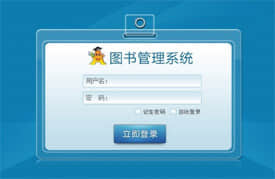
■完成项目:京东电商网站项目、2048游戏项目、智能
图书管理系统

 课程
课程■学习内容:并发编程实战开发
■学习目标:掌握Socket编程模型、NIO与AIO编程模型
Buffer API与通信框架Netty。
■完成项目:类QQ聊天室、RPC模拟实现

 课程
课程■学习内容:Scala函数、Spark SQL、机器学习
■学习目标:搭建负载均衡、高可靠的服务器集群,增
大网站并发访问量,保证服务不间断。
■完成项目:公司网络拓扑实战、构建企业网站和邮件应
用平台 、构建服务器管理监控系统。
 课程
课程■学习内容:Hadoop生态体系
■学习目标:掌握HDFS原理、操作和应用开发,掌握分
布式运算、Hive数据仓库原理及应用。
■完成项目:微博数据大数据分析项目、用户行为分析项
目、精准广告投放项目。
 课程
课程■学习内容:Python实战开发
■学习目标:能够编写网络爬虫、Python进行网络编程
PythonWeb全栈开发、Python机器学习。
■完成项目:Python微博数据爬取、MapReduce设计ETL
Hive计数统计分析、SSM框架可视化分析。
 课程
课程■学习内容:Storm实时开发
■学习目标:掌握Storm程序的开发及底层原理,具备开
发基于Storm的实时计算程序的能力。
■完成项目:实时处理新数据和更新数据库,处理密集查询
并行搜索处理大集合的数据。
 课程
课程■学习内容:Spark生态体系
■学习目标:熟练使用Scala快速开发、Spark进行深入编
程,以及spark大数据调优。
■完成项目:使用Spark处理离线数据、使用Spark
Streaming完成实时计算。

 课程
课程■学习内容:大型综合性大数据项目
■学习目标:能够熟练查询DSL、掌握底层索引控制、索
引段统计与故障处理。
■完成项目:实时索引存储节点,elasticsearch建立索引精
准搜索分析。
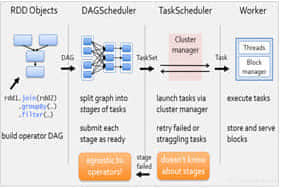
 课程
课程■学习内容:大型综合性大数据项目
■学习目标:熟练Docker安装配置、掌握Docker核心开
发、Docker镜像与数据管理。
■完成项目:docker镜像与容器存储结构分析,使用docker
容器搭建jenkins集群。
 课程
课程■学习内容:大型综合性大数据项目
■学习目标:熟练模型评估与选择,熟练使用机器学习各
种算法,掌握机器学习与大数据的结合。
■完成项目:广告CTR预估及投放,智能数据实时监测项目
社交图谱大数据分析。
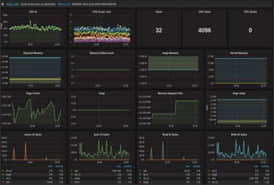
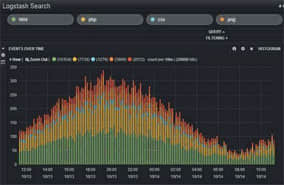 课程
课程■学习内容:超大集群调优
■学习目标:能够熟练进行版本调优、压缩调优、文件调
优、参数调优等八大集群调优。
■完成项目:大数据并发超大集群调优,服务器大集群架构
调优,超大数据资源调优。
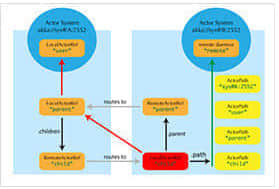
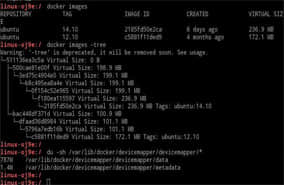 课程
课程■学习内容:大型综合性大数据项目
■学习目标:能够综合运用大数据知识进行非结构化数据
开发、分析,能够开发大型项目。
■完成项目:某大型网站日志分析,移动业务感知分析,实
时检测车辆超速项目,实时非法网站检测项目
| 1.初识Java | 2.流程与控制 | 3.面向对象及方法重载 | 4.访问权限和继承 | 5.抽象类与接口 |
| 1、Java发展简史,主要特征 2、Java运行机制 3、第一个Java程序,注释 4、Javac,Java,Javadoc等命令 5、标识符与关键字 6、变量的声明,初始化与应用 7、变量的作用域 8、变量重名 9、基本数据类型 10、类型转换与类型提升 11、各种数据类型使用细节 12、转义序列 13、各种运算符的使用 |
1、选择控制语句if-else 2、选择控制语句switch-case 3、循环控制语句while 4、循环控制语句do-while 5、循环控制语句for与增强型for 6、break,continue,return 7、循环标签 8、数组的声明与初始化 9、数组内存空间分配 10、栈与堆内存 11、二维(多维)数组 12、Arrays类的相关方法 13、main方法命令行参数 |
1、面向对象的基本思想 2、类与对象 3、成员变量与默认值 4、方法的声明,调用 5、参数传递和内存图 6、方法重载的概念 7、调用原则与重载的优势 8、构造器声明与默认构造器 9、构造器重载 10、this关键字的使用 11、this调用构造器原则 12、实例变量初始化方式 13、可变参数方法 |
1、包的声明与使用 2、import与import static 3、访问权限修饰符 4、类的封装性 5、static(静态成员变量) 6、final(修饰变量,方法) 7、静态成员变量初始化方式 8、类的继承与成员继承 9、super的使用 10、调用父类构造器 11、方法的重写与变量隐藏 12、继承实现多态和类型转换 13、instanceof |
1、抽象类 2、抽象方法 3、继承抽象类 4、抽象类与多态 5、接口的成员 6、静态方法与默认方法 7、静态成员类 8、实例成员类 9、局部类 10、匿名类 11、eclipse的使用与调试 12、内部类对外围类的访问关系 13、内部类的命名 |
| 6.Lambda表达式与常用类 | 7.异常处理与泛型 | 8.集合(上)和集合(下) | 9.I/O流与反射 | 10.Java网络编程与多线程 |
| 1、函数式接口 2、Lambda表达式概念 3、Lambda表达式应用场合 4、使用案例 5、方法引用 6、枚举类型(编译器的处理) 7、包装类型(自动拆箱与封箱) 8、String方法 9、常量池机制 10、String讲解 11、StringBuilder讲解 12、Math,Date使用 13、Calendars使用 |
1、异常分类 2、try-catch-finally 3、try-with-resources 4、多重捕获multi-catch 5、throw与throws 6、自定义异常和优势 7、泛型背景与优势 8、参数化类型与原生类型 9、类型推断 10、参数化类型与数组的差异 11、类型通配符 12、自定义泛型类和类型擦出 13、泛型方法重载与重写 |
1 、常用数据结构 2 、Collection接口 3 、List与Set接口 4 、SortedSet与NavigableSet 5 、相关接口的实现类 6 、Comparable与Comparator 7、Queue接口 8 、Deque接口 9 、Map接口 10、NavigableMap 11、相关接口的实现类 12、流操作(聚合操作) 13、Collections类的使用 |
1 、File类的使用 2 、字节流 3 、字符流 4 、缓存流 5 、转换流 6 、数据流 7、对象流 8、类加载,链接与初始化 9 、ClassLoader的使用 10、Class类的使用 11、通过反射调用构造器 12、安全管理器 |
1、进程与线程 2、创建线程的方式 3、线程的相关方法 4、线程同步 5、线程死锁 6、线程协作操作 7、计算机网络(IP与端口) 8、TCP协议与UDP协议 9、URL的相关方法 10、访问网络资源 11、TCP协议通讯 12、UDP协议通讯 13、广播 |
| 1.Mysql | 2.Jdbc | 3.HTML | 4.CSS | 5.Javascript |
| 1、数据库基础知识 2、SQL理论基础和数据类型 3、DDL、DML、DQL语句 4、函数和关联查询 5、子查询、约束、视图 6、编程 存储过程,触发器 7、Sql查询案例和优化 |
1、Jdbc基本概念 2、使用Jdbc连接数据库 3、使用Jdbc进行crud操作 4、使用Jdbc进行多表操作 5、Jdbc驱动类型 6、Jdbc异常和批量处理 7、Jdbc储存过程 |
1、Html基本介绍 2、HTML语法规范 3、基本标签介绍 4、表单介绍 5、Table标签 6、DIV布局介绍 7、HTML列表详解 |
1、CSS简介及文字样式 2、盒子模型 3、布局及定位 4、CSS选择器 5、CSS3动画效果 6、CSS3新增选择器 7、案例 |
1、JavaScript简介 2、基本语法规则 3、if判断语句和for循环语句 4、函数、事件 5、内置对象和自定义对象 6、DOM操作 7、表单验证 |
| 6.Jquery | 7.Servlet+Jsp | 8.Springmvc+ | 9.Mybatis | 10.Maven+Svn |
| 1、Jquery简介 2、Jquery选择器 3、Jquery中事件操作 4、Jquery的动画效果 5、使用Jquery完成Dom操作 6、Jquery封装函数 7、Jquery案例 |
1、Servlet简介 2、Request对象 3、Response对象 4、转发和重定向 5、使用Servlet完成Crud 6、Session和Coolie简介 7、ServletContext和Jsp 8、El和Jstl的使用 |
1、Springmvc简介 2、用Springmvc第一个项目 3、Springmvc执行流程和参数 4、Springmvc 5、Springmvc数据回显 6、结果返回类型 7、文件上传及Ajax 8、拦截器 |
1、Mybatis简介 2、Mybatis配置文件解析 3、用Mybatis完成crud操作 4、ResultMap的使用 5、Mybatis关联查询 6、动态sql语句 7、Mybatis缓存 8、Mybatis-Generator |
1、Ioc、Aop、Ssm整合 2、Svn的简介 3、Svn的安装 4、Svn在集成环境中使用 5、Maven简介及安装 6、使用Maven开发项目 |
| 1.Socket编程编程 | 2.伪异步IO编程 | 3.NIO与AIO编程模型 | 4.Buffer API讲解 | 5.通信框架Netty |
| 1、网络中进程之间如何通信 2、Socket是什么 3、socket的基本操作 4、socket类型讲解 5、socket基本函数 6、socket高级函数 7、socket中TCP交换分组 8、socket中TCP高级编程 |
1、用户空间和内核空间 2、同步和异步/阻塞与非阻塞 3、伪异步IO编程基础 4、伪异步IO模型图 5、伪异步式IO创建TimeServer 6、伪异步IO弊端分析 7、伪异步IO编程实战 |
1、网络编程模型基本认识 2、BIO、NIO、AIO适用场景 3、同步阻塞 I/O 4、同步非阻塞 I/O 5、异步阻塞 I/O 6、异步非阻塞 I/O(AIO) 7、NIO与AIO基本操作 8、高性能IO设计模式 |
1、缓冲区的四个属性 2、相对存取和绝对存取 3、翻转与释放 4、创建缓冲区 5、缓冲区类型与操作 6、缓冲区比较 7、ByteBuffer 类存取和转化 |
1、Netty 基本认识 2、Netty 架构特征详解 3、Netty行业应用 4、Netty 框架基本操作 5、Netty 和 Mina比较 6、缓冲区比较 7、ByteBuffer 类存取和转化 |
| 1.Linux安装与配置 | 2.系统管理与目录管理 | 3.用户与用户组管理 | 4.Shell编 程 | 5.服务器配置 |
| 1、安装Linux至硬盘 2、获取信息和搜索应用程序 3、进阶:修复受损的Grub 4、关于超级用户root 5、依赖发行版本的系统管理工具 6、关于硬件驱动程序 7、进阶:配置Grub 8、CSS预处理器LESS框架使用; 9、CSS组件框架编写。 |
1、Shell基本命令 2、使用命令行补全和通配符 3、find命令、locate命令 4、查找特定程序:whereis 5、Linux文件系统的架构 6、移动、复制和删除 7、文件和目录的权限 8、文件类型与输入输出 9、vmware介绍与安装使用 10、网络管理、分区挂载 |
1、软件包管理 2、磁盘管理 3、高级硬盘管理RAID和LVM 4、进阶:备份你的工作和系统 5、用户与用户组基础 6、管理、查看、切换用户 7、/etc/...文件 8、进程管理 9、linux VI编辑器,awk,cut,grep,sed,find,unique等 |
1、 SHELL变量 2、传递参数 3、数组与运算符 4、SHELL的各类命令 5、SHELL流程控制 6、SHELL函数 7、SHELL输入/输出重定向 8、SHELL文件包含 |
1、系统引导 2、管理守护进程 3、通过xinetd启动SSH服务 4、配置inetd 5、Apache基础 6、设置Apache服务器 7、使用PHP+MySQL |
| 1. Hadoop起源与安装 | 2.HDFS分布式文件系统 | 3.Hadoop文件I/O详解 | 4.MapReduce工作原理 | 5.MapReduce编程开发 |
| 1、大数据概论 2、 Google与Hadoop模块 3、Hadoop生态系统 4、Hadoop常用项目介绍 5、Hadoop环境安装配置 6、Hadoop安装模式 7、Hadoop配置文件 |
1、认识HDFS及其HDFS架构 2、Hadoop的RPC机制 3、HDFS的HA机制 4、HDFS的Federation机制 5、 Hadoop文件系统的访问 6、JavaAPI接口与维护HDFS 7、HDFS权限管理 8、hadoop伪分布式 |
1、Hadoop文件的数据结构 2、 HDFS数据完整性 3、文件序列化 4、Hadoop的Writable类型 5、Hadoop支持的压缩格式 6、Hadoop中编码器和解码器 7、 gzip、LZO和Snappy比较 8、HDFS使用shell+Java API |
1、MapReduce函数式编程概念 2、 MapReduce框架结构 3、MapReduce运行原理 4、Shuffle阶段和Sort阶段 5、任务的执行与作业调度器 6、自定义Hadoop调度器 7、 异步编程模型 8、YARN架构及其工作流程 |
1、WordCount案例分析 2、输入格式与输出格式 3、压缩格式与MapReduce优化 4、辅助类与Streaming接口 5、MapReduce二次排序 6、MapReduce中的Join算法 7、从MySQL读写数据 8、Hadoop系统调优 |
| 6.Hive数据仓库工具 | 7.Hive深入解读 | 8.Sqoop与Oozie | 9.Zookeeper详解 | 10.开源数据库HBase |
| 1、Hive工作原理、类型及特点 2、Hive架构及其文件格式 3、Hive操作及Hive复合类型 4、Hive的JOIN详解 5、Hive优化策略 6、Hive内置操作符与函数 7、Hive用户自定义函数接口 8、Hive的权限控制 |
1 、Hive开发环境的搭建 2 、Hive的三种连接方式 3 、Hive的DDL 4 、Hive的DML 5 、Hive数据类型 6 、Hive特殊分隔符处理 7、Hive启动shell配置 8、Hive数据倾斜 |
1 、安装部署Sqoop 2、Sqoop数据迁移 3、Sqoop使用案例 4、深入了解数据库导入 5、导出与事务 6、导出与SequenceFile 7、Azkaban执行工作流 |
1、Zookeeper简介 2、Zookeeper的下载和部署 3、Zookeeper的配置与运行 4、Zookeeper的本地模式实例 5、Zookeeper的数据模型 6、Zookeeper命令行操作范例 7、storm在Zookeeper目录结构 |
1、HBase的特点 2、HBase访问接口 3、HBase存储结构与格式 4、HBase设计 5、关键算法和流程 6、HBase安装 7、HBase的SHELL操作 8、HBase集群搭建 |
| 1. Python入门开发 | 2.Python核心编程 | 3.Python网络编程 | 4.Python Web全栈开发 | 5.Python机器学习 |
| 1、Python对象、数字、序列 2、 Python映像和集合类型 3、Python条件和循环 4、Python文件和输入输出 5、Python错误和异常 6、函数和函数式编程 7、Python面向对象编程 |
1、Python正则表达式 2、Python函数编程 3、Python多线程编程 4、Python图形用户界面编程 5、Python数据库编程 6、创建Python扩展 7、Python核心编程 |
1、客户端/服务器架构 2、客户端/服务器网络编程 3、Python面向连接与无连接 4、创建TCP服务器与客户端 5、创建UDP服务器与客户端 6、Socket模块属性 7、Python和FTP/SMTP |
1、创建Web客户端 2、 urlparse/urllib/urllib2模块 3、高级Web客户端 4、建立CGI应用程序 5、建立Web服务器 6、全面交互的Web站点 7、高级CGI |
1、机器学习基础技巧 2、 科学计算 Python 软件包 3、使用 Python 学习机器学习 4、Python 机器学习基本算法 5、Python 进阶机器学习算法 6、Python 深度学习 7、 Python 机器学习实战 |
| 1. storm简介与基本知识 | 2.拓扑详解与组件详解 | 3.spout详解 与bolt详解 | 4.storm安装与集群搭建 | 5.Kafka |
| 1、storm的诞生诞生与成长 2、storm的优势与应用 3、storm基本知识概念和配置 4、序列化与容错机制 5、可靠性机制—保证消息处理 6、storm开发环境与生产环境 7、storm拓扑的并行度 8、storm命令行客户端 |
1、流分组和拓扑运行 2、拓扑的常见模式 3、本地模式与stormsub的对比 4、 使用非jvm语言操作storm 5、hook、组件基本接口 6、基本抽象类 7、事务接口 8、组件之间的相互关系 |
1、spout获取数据的方式 2、常用的spout 3、学习编写spout类 4、bolt概述 5、可靠的与不可靠的bolt 6、复合流与复合anchoring 7、 使用其他语言定义bolt 8、学习编写bolt类 |
1、storm集群安装步骤与准备 2、本地模式storm配置命令 3、配置hosts文件、安装jdk 4、zookeeper集群的搭建 5、部署节点 6、storm集群的搭建 7、zookeeper应用案例 8、Hadoop高可用集群搭建 |
1、Kafka介绍和安装 2、整合Flume 3、Kafka API 4、Kafka底层实现原理 5、Kafka的消息处理机制 6、数据传输的事务定义 7、Kafka的存储策略 |
| 6.Flume | 7.Redis | |||
| 1、Flume介绍和安装 2、Flume Source讲解 3、Flume Channel讲解 4、Flume Sink讲解 5、flume部署种类、流配置 6、单一代理、多代理说明 7、flume selector相关配置 |
1、Redis介绍和安装、配置 2、Redis数据类型 3、Redis键、字符串、哈希 4、Redis列表与集合 5、Redis事务和脚本 6、Redis数据备份与恢复 7、Redis的SHELL操作 |
| 1.Scala编程开发 | 2.Scala深入解析 | 3.SparKcore编程 | 4. Sparkcore深入编程 | 5.SparkSQL |
| 1、Scala语法基础 2、idea工具安装 3、maven工具配置 4、条件结构、循环、高级for循环 5、数组、映射、元组 6、类、样例类、对象、伴生对象 7、高阶函数与函数式编程 |
1、 柯里化、闭包 2、模式匹配、偏函数 3、类型参数 4、协变与逆变 5、隐式转换、隐式参数、隐式值 6、Actor机制 7、高级项目案例 |
1、Spark四大特性 2、Wordcount案例演示 3、什么是RDD 4、Spark架构 5、Spark集群搭建/HA集群搭建 6、Spark任务提交 7、TransFormation和Action |
1、算子演示(Scale、jdk7、jdk8) 2、RDD持久化 3、宽依赖和窄依赖 4、累加变量和共享变量 5、Spark运行模式 6、二次排序 7、综合案例演示 |
1、Spark的前世今生 2、什么是DataFrame 3、什么是DataSet 4、RDD转换为DataSet 5、load/save 6、数据源之json |
| 6.深入SparkSQL | 7.Spark Streaming | 8.SparkGraphX | 9.Spark源码导读 | 10.Spark调优 |
| 1、数据源之parquet 2、数据源之Hive/Hbase/Mysql 3、thrift服务 4、开窗函数 5、UDF、UDAF编程 6、综合案例演示 |
1、Spark Streaming运行流程 2、什么是DStream 3、UpdateStateByKey算子演示 4、CheckPoint与DriverHA实现 5、Transform算子演示 6、ForeachRDD重点算子详解 7、与Kafka和Flume整合 |
1、GraphX应用背景 2、GraphX的框架 3、GraphX实现分析 4、GraphX图计算 5、GraphX核心概念解释 6、GraphX框架实现分析 7、GraphX案例演示 |
1、启动脚本流程分析 2、Mater和Worker启动流程 3、资源分配算法 4、SparkContext初始化 5、TaskScheduler运行 6、task位置算法与分配算法 7、DagScheduler运行流程 8、stage划分算法 |
1、JVM调优 2、开发调优 3、数据倾斜调优 4、资源调优 5、shuffle调优 6、sparkSQL调优 7、sparkStreaming调优 |
| 1.ElasticSearch简介 | 2.查询DSL进阶 | 3.底层索引控制 | 4.索引段统计与故障处理 | 5.ElasticSearch Java API |
| 1、Lucene的总体架构 2、Lucene查询语言 3、ElasticSearch简介 4、ElasticSearch的基本概念 5、ElasticSearch架构背后的关键 6、ElasticSearch的工作流程 |
1、Apache Lucene评分公式解释 2、何时文档被匹配上 3、TF/IDF评分公式 4、查询改写与二次评分 5、前缀查询范例与查询改写属性 6、数据更新API 7、使用过滤器优化查询 |
1、相似度模型配置 2、实时、提交、更新及事务日志 3、深入理解数据处理 4、控制索引合并 5、分布式索引架构 6、调整默认的分片分配行为 7、调整分片分配 |
1、segments API简介 2、 索引段信息的可视化 3、过滤器缓存与字段数据缓存 4、处理垃圾回收问题 5、UNIX中避免内存交换 6、关于I/O调节与热点线程 7、用预热器提升查询速度 |
1、ElasticSearch Java API简介 2、连接到集群 3、API剖析与CRUD操作 4、ElasticSearch查询 5、批量执行多个操作 6、构造JSON格式的查询和文档 7、管理API |
| 1.初识容器与Docker | 2.核心概念与安装配置 | 3.Docker镜像使用 | 4.Docker数据管理 | 5.Docker与大数据 |
| 1、基本容器认识 2、虚拟化技术与容器 3、容器关键技术介绍 4、Docker 基本认识 5、Docker 特征 6、Docker 组件与元素 7、虚拟化与Docker |
1、Docker核心概念 2、使用脚本安装 Docker 3、启动docker 后台服务 4、CentOS Docker 安装 5、使用脚本安装 Docker 6、Windows Docker 安装 7、运行 Docker |
1、Docker镜像关键概念 2、Docker镜像操作解析 3、Docker容器的迁移方法 4、存储驱动的功能与管理 5、Docker架构概览 6、client模式与daemon模式 7、Docker高级实践技巧 |
1、数据卷与数据卷容器 2、 Docker数据容器 3、挂载本地的目录到容器里 4、挂载数据卷 5、定义数据卷容器 6、数据卷的备份与恢复 7、数据卷容器迁移数据 |
1、在Docker创建Hadoop镜像 2、获取Docker镜像库 3、SSH功能镜像文件生成 4、生成Hadoop镜像库文件 5、Docker配置三节点Hdfs集群 6、Docker配置三节点Yarn集群 7、Docker配置三节点spark集群 |
| 1.模型评估与选择 | 2.线性模型与决策树 | 3.K最近邻算法 | 4.贝叶斯分类器 | 5.机器学习与大数据 |
| 1、机器学习基本认识 2、经验误差与过拟合 3、评估方法 4、性能度量 5、比较检验 6、偏差与方差 |
1、基本形式与线性回归 2、对数几率回归 3、线性判别分析与多分类学习 4、决策树基本流程 5、决策树划分选择与剪枝处理 6、连续与缺失值 7、多变量决策树 |
1、K最近邻算法概念介绍 2、K最近邻算法偏差与方差 3、K最近邻算法最近邻搜索 4、K最近邻算法K近邻搜索 5、K最近邻算法算法原理 6、K最近邻算法各类算法实现 7、K最近邻算法案例演示 |
1、贝叶斯决策论 2、极大似然估计 3、朴素贝叶斯分类器 4、半朴素贝叶斯分类器 5、贝叶斯网 6、EM算法 |
1、机器学习的范围 2、大数据下的机器学习 3、大数据对机器学习的影响 4、机器学习与大数据项目 5、模式识别与大数据 6、深度学习与大数据 7、机器学习与大数据 |
项目简介
该项目使用hadoop分布式爬虫爬取互联网各大电商网站数据,通过各类海量数据的爬行抓取,前台实现实时对数据的快速精准查询和商品对比以及业务分析。
项目特色
该项目包含商品页面抓取和解析,分布式爬虫设计细节,分析URL链接和页面内容如何存储,分布式爬虫监控功能。爬虫频繁爬取数据IP被封问题解决方案,爬虫爬取失败URL如何处理,抓取需要登录的网站数据。使用solr实现海量数据精准查询,使用hbase实现海量数据精准快速查询。本项目包含的大数据技术有:Java、HttpClient、Redis、Solr、HBase、Zookeeper、HighChart、HTMLEmail。
项目简介
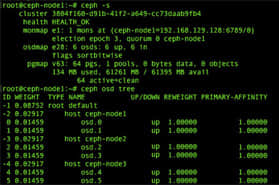
该项目实现对数据系统的高频日志数据进行实时收集和业务处理,在高峰期每秒钟会有近万HTTP请求发送到服务器上,这些请求包含了用户行为和个性化推荐请求。从这些数据中快速挖掘用户兴趣偏 好并作出效果不错的推荐。
项目特色
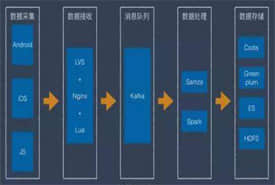
Web应用云包含了所有直接面对用户的Web服务,每个Web应用都会产生Web日志以及其他实时数据,这些数据一 方面会及时交由实时计算框架进行处理,另一方面也会定期同步至离线计算框架;实时计算框架会处理接收到的实时数据,并将处理结果输出到数据查询框架或者离 线计算框架。
项目简介
通过大数据工具将互联网中的日志采集、清洗、分析统计出常见的互联网指标;开发出各种维度UV的分析报表、各个指标每日、每月指标报表分析,用于对产品做出正确的决策,数据的正确性校对问题,临时性图标的开发。
项目特色
使用hadoop、mapreduce、hive清理和分析UV、PV、登陆、留存等常见指标,使用storm实时分析充值、消费等趋势,各个维度的趋势对比、各个指标每日、月指标报表生成,使用kettle数据的正确性校对问题和邮件报警。日志数据的实时采集优先采用Flume-Ng组件,Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
项目简介
该项目主要利用hadoop集群强大的计算能力对移动的大批量离线话单数据进行分析,统计移动使用业务(流量套餐、话费套餐、铃声套餐等)情况,达到感知用户行为和使用习惯,确定移动业务推广走向的一套系统。
项目特色
使用MR对多个小区GN口五类数据进行分析完成和移动用户通话时长、2G/3G业务流量使用进行一级汇总,列出小区流量使用排名,使用hive完成用户维度关联汇总,统计话单使用情况,使用spark完成APP下载top排名统计,使用sparkstreaming实时处理,根据用户使用APP,实时统计排名,使用sqoop导入oracle完成的web页面2G/3G业务使用排名和流量排名。
项目简介
通过jdbc的方式连接spark的thriftserver,通过集群进行HDFS上的大宽表的运算求count。这样便可以定位相应的客户数量,从而进行客户群、标签的分析,产品的策略匹配从而精准营销。
项目特色
1、数据指标的的梳理来源于各个系统日常积累的日志记录系统,通过sqoop导入hdfs,或者spark的jdbc连接传统数据库进行数据的cache。
2、通过hive编写UDF 或者hiveql 根据业务逻辑拼接ETL,使用户对应上不同的用户标签数据,生成相应的源表数据,以便于后续用户画像系统,通过不同的规则进行标签宽表的生成。
项目简介
针对现有技术的缺陷,提供一种基于实时日志的网站威胁检测方法及系统,能够提高日志数据的处理能力及时效性,提高网站威胁检测与反应的及时性,降低网站运行的风险,为网络的信息安全提供有力的保障。
项目特色
日志数据实时采集单元,用于实时采集监控网站日志服务器上的日志数据,日志数据实时转换与分发单元,用于对日志数据进行转换与实时分发;日志数据实时处理与检测单元,用于对日志数据进行实时处理与检测;日志数据实时监控单元,用于对所述网站威胁检测结果进行展示,并根据所述检测结果的严重程度进行预警。

哈尔滨工业大学
东北石油大学
黑龙江外国语大学
北京工业大学
内蒙古民族大学
山西大学
中国石油大学
内蒙古财经大学
太原理工大学











