光环大数据开发 再度升级9.0
2. 超大集群调优、机器学习、Docker容器引擎、ElasticSearch、Python实战开发、并发编程等均为光环大数据研发课程!
2. 为保障学员吸收效果,课程中所有模块、流程、原理、阶段等均由老师现场原创画图解读!(其他机构大都按照PPT照本宣读)
-
90+次课程研讨
-
53+次课程全新升级
-
8+6+24阿里云+企业+案例
-
46+次企业技术迭代
-
14280+元薪资
课程设置
- 阶段一:JavaSE开发
- 阶段二:JavaEE开发
- 阶段三:Linux精讲
- 阶段四:JavaSE增强(新增)
- 阶段五:Hadoop生态体系
- 阶段六:Storm实时流式处理
- 阶段七:Scala编程语言(优化)
- 阶段八:Spark生态体系
- 阶段九:ElasticSearch搜索引擎
- 阶段十:Flink精讲
- 阶段十一:机器学习
- 阶段十二:超大集群调优 查看完整课程大纲
课程一阶段
学习目标:
掌握Java流程控制和数组、面向对象、集合框架、异常和泛型和注解、IO流、并发编程等知识。完成项目:
Java多线程模拟多窗口售票,Java集合框架管理。

第一阶段主要内容:
- 1、Java编程语言简介
- 2、Java环境搭建
- 3、第一个Java程序
- 4、Java,Javac等命令
- 5、标识符与关键字
- 6、String和常量池
初识Java
- 1、if-else条件控制
- 2、while循环控制
- 3、for循环控制
- 4、switch-case条件控制
- 5、break和continue
- 6、数组的定义和使用
流程控制与数组
- 1、面向对象的基本思想
- 2、成员变量和方法
- 3、属性和方法权限控制
- 4、final和static、import
- 5、抽象类和接口
- 6、继承和实现,重写和重载
面向对象及方法重载
- 1、多线程和并发的概念
- 2、Thread和Runnable详解
- 3、start方法和run方法详解
- 4、线程的生命周期详解
- 5、线程同步和锁
- 6、sleep,阻塞,join
并发编程
课程二阶段
学习目标:
掌握数据库MySQL和SQL、Maven、Git/SVN、MyBatis/Hibernate、Spring、SSM整合。完成项目:
京东电商网站项目、2048游戏项目、智能图书管理系统。
第二阶段主要内容:
- 1、数据库系统概念及
- 2、数据库和表概念和操作
- 3、SQL语法:增删改查
- 4、数据库事务详解
- 5、SQL查询优化和建表设计
- 6、触发器和存储过程详解
数据库MySQL和SQL
- 1、项目构建:Maven
- 2、版本管理:Git/SVN
- 3、代码审查:Findbugs
- 4、自动测试:Junit/TestNG
- 5、继承开发:IDEA/Eclipse
- 6、持续集成:Jenkins
Maven、Git/SVN
- 1、MyBatis概念和作用
- 2、实现基本增删改查
- 3、动态代理实现DAO
- 4、SQLMapConfig详解
- 5、Mapper配置文件详解
- 6、MyBatis动态SQL
MyBatis/Hibernate
- 1、Spring概念及作用
- 2、Spring的IOC和DI
- 3、Bean生命周期管理
- 4、IOC初始化和源码解析
- 5、代理设计模式
- 6、SpringAOP面向切面编程
Spring
课程三阶段
学习目标:
掌握VMWare虚拟机安装和使用、Linux文件系统、Linux文本编辑命令Vim、Linux网络管理等。完成项目:
公司网络拓扑实战、构建企业网站和邮件应用平台、构建服务器管理监控系统。
第三阶段主要内容:
- 1、Linux操作系统介绍
- 2、Linux系统架构认识
- 3、Linux的启动级别和终端
- 4、Linux的常用命令分类
- 5、Linux的常使用命令详解
- 6、Linux操作系统基础运维
VMWare虚拟机安装和使用
- 1、Linux磁盘挂载和管理
- 2、命令详解:cd,pwd,ls
- 3、touch,file,mkdir
- 4、cp,mv,rename,rm,rmdir
- 5、命令详解:du,df
- 6、操作符:!! !$ | > >>等
Linux文件系统
- 1、Vim文本编辑器概念
- 2、Vim编辑器的三种模式
- 3、基本使用:模式转换
- 4、基本使用:光标移动
- 5、高级使用:查找和替换
- 6、多文本编辑和宏
Linux文本编辑命令Vim
- 1、IFconfig命令详解
- 2、Vmware三种网络连接
- 3、NAT网络连接配置详解
- 4、DNS概念详解和配置
- 5、常用网络管理命令详解
- 6、常用监控脚本编写
Linux网络管理
课程四阶段
学习目标:
掌握Java编程语言中集合、反射、并发编程、网络编程、设计模式、数据结构和算法等高阶常用。完成项目:
类QQ聊天室、RPC模拟实现。

第四阶段主要内容:
- 1、Collection体系详解
- 2、Map详解及源码阅读
- 3、Iterable和Iterator
- 4、Collections和Arrays
- 5、Comparator和Comparable详解
- 6、15种排序算法概述
集合和排序
- 1、面向对象的终极奥义理解
- 2、一切皆对象
- 3、Class、Method、Constructor、Field详解
- 4、单例和工厂方法模式
- 5、责任链和策略模式
- 6、代理设计模式
反射和设计模式
- 1、进程和线程、并行和并发
- 2、多线程的实现和状态详解
- 3、java的内存模型
- 4、synchronized和lock
- 5、原子量、volatile等
- 6、JDK1.5新特性:并发包
并发编程/多线程
- 1、数据结构的概念及用途
- 2、线性表:数组详解
- 3、线性表:链表详解
- 4、队列,栈,Hash表详解
- 5、树详解(平衡树,B树等)
- 6、堆详解(大根堆,小根堆)
数据结构
课程五阶段
学习目标:
掌握Common和RPC、HDFS分布式文件系统、MapReduce分布式编程模型、YARN资源调度系统等。完成项目:
微博数据大数据分析项目、用户行为分析项目、精准广告投放项目。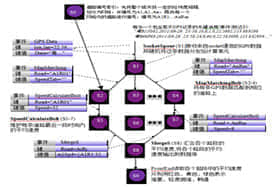
第五阶段主要内容:
- 1、普通文件系统理解
- 2、超大数据集的存储
- 3、如何设计分布式文件系统
- 4、使用Hadoop的RPC实现
分布式文件系统 - 5、分布式文件系统HDFS
- 6、HDFS的组织架构和机制
HDFS分布式文件系统
- 1、普通单机计算程序理解
- 2、超大数据集的计算思路
- 3、如何设计分布式计算引擎
- 4、设计分布式计算引擎
- 5、详解Hadoop分布式计算
引擎MapReduce - 6、MapReduce的编程套路
MapReduce编程模型
- 1、普通资源调度系统
- 2、多节资源调度解决思路
- 3、设计分布式资源调度引擎
- 4、设计分布式资源调度系统
- 5、详解Hadoop的分布式资
源调度系统YARN - 6、YARN的资源调度算法
YARN资源调度系统
- 1、数据库的事务相关复习
- 2、分布式一致性理解
- 3、CAP理论和BASE理论
- 4、分布式一致性算法详解
- 5、ZooKeeper架构和使用
- 6、ZooKeeper工作机制详解
ZooKeeper协调服务
课程六阶段
学习目标:
能够熟练使用Flume分布式数据采集工具、Kafka分布式消息系统、Storm分布式流式计算引擎等。完成项目:
实时处理新数据和更新数据库,处理密集查询并行搜索处理大集合的数据。
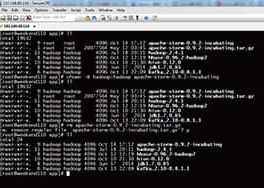
第六阶段主要内容:
- 1、Flume产生背景
- 2、Flume概念和作用
- 3、Flume体系结构核心
- 4、Flume经典案例实战部署
- 5、Flume自定义拦截器
- 6、Flume的高可用架构
Flume分布式数据采集
- 1、JMS技术规范
- 2、消息队列和消息系统阐述
- 3、Kafka的概念和优势分析
- 4、Kafka的集群部署及存储
- 5、Kafka的shell操作
- 6、Kafka的API操作
Kafka分布式消息系统
- 1、流式应用计算需求思路
- 2、设计流式应用计算引擎
- 3、Storm产生及应用背景
- 4、Storm集群搭建概念
- 5、Storm WordCount运行
- 6、Storm并发度计算机制
Storm流式计算引擎
- 1、超大数据集的增删改查
- 2、MySQL实时增删改查
- 3、设计实现分布式数据库
- 4、Hbase产生背景详解
- 5、HBase集群搭建管理
- 6、HBase Shell及API操作
HBase分布式数据库
课程七阶段
学习目标:
掌握Scala编程语言基础语法、Scala面向对象、Scala函数式编程、Scala的并发编程和Spark的RPC。完成项目:
记录用户行为、统计页面转化率,热门商品及黑名单统计
第七阶段主要内容:
- 1、Scala概述及环境安装
- 2、Scala的入门程序
- 3、Scala变量和数据类型
- 4、Scala编码规范及流程
- 5、Scala函数和方法的定义
- 6、Scala的定长和变长数组
Scala编程语言基础语法
- 1、Scala类的定义和使用
- 2、Scala的构造器
- 3、Scala的对象
- 4、Scala抽象类的定义
- 5、Scala Trait的使用
- 6、Scala的模式匹配
Scala面向对象
- 1、Scala的高阶函数
- 2、Scala的闭包和柯里化
- 3、Scala的隐式转换
- 4、Scala的泛型基础
- 5、Scala的类型界定
- 6、Scala的上界和下界
Scala函数式编程
- 1、Scala的Actor概念详解
- 2、Akka并发编程框架使用
- 3、RPC的概念和工作原理
- 4、HadoopRPC的使用
- 5、Akka实现一个聊天程序
- 6、Akka模拟实现YARN
Scala的并发编程
课程八阶段
学习目标:
熟练使用Spark、Spark Core、Spark内核设计和源码阅读、Spark SQL等进行快速开发。完成项目:
使用Spark处理离线数据、使用SparkStreaming完成实时计算。
第八阶段主要内容:
- 1、Spark产生背景
- 2、Spark的特点和优势分析
- 3、Spark模块和应用场景
- 4、Spark的集群安装
- 5、Spark的第一个应用程序
- 6、Spark Shell的使用详解
Spark编程开发
- 1、Spark应用程序流程分析
- 2、RDD的概念和属性分析
- 3、RDD的宽窄依赖原理
- 4、Transformation/Action
- 5、Spark DAG/Stage分析
- 6、持久化cache和persist
Spark Core
- 1、SparkSQL的作用及发展
- 2、SparkSession详解和SparkContext对比分析
- 3、Spark数据抽象详解
- 4、SparkSQL代码编写
- 5、SparkSQL的save和load
- 6、SparkSQL整合Hive
Spark SQL
- 1、Storm实现流式处理思路
- 2、SparkStreaming实现流
式处理的思路分析 - 3、StreamingContext详解
- 4、数据抽象Dstream详解
- 5、SparkStreaming运行机制
- 6、SparkStreaming工作原理
Spark Streaming
课程九阶段
学习目标:
能够掌握ElasticSearch核心概念、安装部署、查询和分析、存储机制等能力。完成项目:
实时索引存储节点,elasticsearch建立索引精准搜索分析。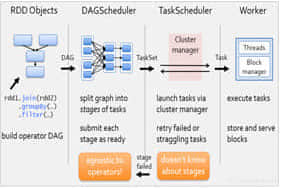
第九阶段主要内容:
- 1、Lucene作用和工作机制
- 2、Solr作用和工作机制
- 3、ElasticSearch产生背景
- 4、Index索引详解
- 5、分布式文档系统原理和倒排索引
- 6、分布式搜索引擎原理
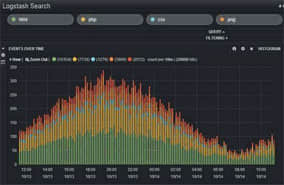
ElasticSearch核心概念
- 1、在windows安装和使用
- 2、在linux安装和使用
- 3、head插件安装
- 4、IK分词插件安装
- 5、kibana插件安装
- 6、LogStash组件安装
ElasticSearch安装部署
- 1、集群状态查询
- 2、index增删改查
- 3、document增删改查
- 4、mget批量查询
- 5、bulk批量增删改
- 6、范围查询、下钻分析
ElasticSearch查询和分析
- 1、ES分布式架构、扩容
- 2、分片&副本分配机制
- 3、document的核心元数据
- 4、document数据路由原理
- 5、文档的全量替换
- 6、ES的延迟删除机制
ElasticSearch存储机制
课程十阶段
学习目标:
熟练Flink简介、Flink架构和集群安装、Flink应用案例、Flink原理分析。完成项目:
Kafka对接Flink的消费数据展示及整合、高吞吐。
第十阶段主要内容:
- 1、流式处理特性分析
- 2、实现流式处理思路分析
- 3、Flink的流式处理思路
- 4、Flink的API支持
- 5、Flink的Libraries支持
- 6、Docker Flink的整合支持
Flink简介
- 1、主从架构和对等架构分析
- 2、Flink的主从架构分析
- 3、Client分析
- 4、Flink的任务调度详解
- 5、Flink的容错详解
- 6、Flink的集群环境安装
Flink架构和集群安装
- 1、Flink实现社交好友分析
- 2、Flink实现离线日志分析
- 3、Flink实现影评分析
- 4、Flink实现NBA数据分析
- 5、Flink实现电商用户画像
- 6、Flink实现金融防欺诈
Flink应用案例
- 1、Flink调度分析
- 2、Flink生成执行计划流程
- 3、Flink生成执行计划源码
- 4、Flink物理执行图
- 5、生成消费原理
- 6、Task的任务分配详解
Flink原理分析
课程十一阶段
学习目标:
熟练模型评估与选择,熟练使用机器学习各种算法,掌握机器学习与大数据的结合。完成项目:
广告CTR预估及投放,智能数据实时监测项目社交图谱大数据分析。
第十一阶段主要内容:
- 1、Python基础语法增强
- 2、计算库Numpy数据结构
- 3、计算库Numpy矩阵详解
- 4、计算库Numpy常用函数
- 5、处理库Pandas数据读取
- 6、可视化库MatplotLib
Python工具库实战
- 1、机器学习概念和分类
- 2、监督学习和无监督学习
- 3、聚类和分类
- 4、经验误差和过拟合欠拟合
- 5、采样和模型评估和选择
- 6、评估方法和性能度量
机器学习基础理论概述
- 1、KNN最近邻算法原理
- 2、决策树和随机森林原理
- 3、支持向量机原理和案例
- 4、逻辑回归和梯度下降详解
- 5、线性回归原理
- 6、K-Means聚类算法详解
机器学习入门
- 1、数据挖掘详细分析
- 2、AdaBoost原理详解
- 3、Aproiri原理详解
- 4、GBDT原理和SKLearn
- 5、HMM隐马尔可夫模型
- 6、CNN卷积神经网络详解
机器学习进阶
课程十二阶段
学习目标:
能够熟练进行版本调优、压缩调优、文件调优、参数调优等八大集群调优。完成项目:
大数据并发超大集群调优,服务器大集群架构调优,超大数据资源调优。
第十二阶段主要内容:
- 新增课程
- 特色课程
JavaSE增强新增课程:网络编程BIO、NIO、Netty
1、网络编程概念和用途;2、网络编程模型概述;3、BIO编程模型案例实现;4、NIO的产生和详述;5、NIO的三大组件详解;6、NIO的编程案例实现;7、Netty的架构详解;8、Netty的应用案例:分布式文件系统实现;Flink精讲新增课程:Flink原理分析
1、Flink调度分析;2、Flink生成执行计划流程分析;3、Flink生成执行计划源码分析;4、JobGraph的生成和源码分析;5、ExcutionGraph的生成和源码分析;6、物理执行图;7、生成消费原理;8、Task的任务分配详解;机器学习新增课程:机器学习进阶
1、数据挖掘详细分析;2、AdaBoost原理详解;3、Aproiri原理详解;4、GBDT原理和SKLearn实现;5、HMM隐马尔可夫模型;6、深度学习神经网络及TensorFlow;7、CNN卷积神经网络详解;8、RNN循环神经网络详解;-
集合和排序
集合排序
1、Collection体系详解和源码阅读;2、Map体系详解和源码阅读;3、Iterable和Iterator深入详解;4、工具类Collections和Arrays;5、Comparator和Comparable详解;6、15种排序算法概述;7、归并排序,快速排序,堆排序等;8、各种排序算法的优劣对比; -
反射和设计模式
反射和设计模式
1、面向对象的终极奥义理解;2、一切皆对象;3、Class,Method,Constructor,Field详解;4、单例和工厂方法模式;5、责任链和策略模式;6、代理设计模式;7、装饰器和适配器设计模式;8、观察者和解释器设计模式; -
并发编程 / 多线程
并发编程/多线程
1、进程和线程、并行和并发;2、多线程的实现和状态详解;3、java的内存模型;4、synchronized和lock两种同步方式;5、原子量,volatile,ThreadLocal等;6、JDK1.5的新特性:并发包详解;7、线程池详解;8、Java并发消息队列详解; -
数据结构
数据结构
1、数据结构的概念,分类和用途;2、线性表:数组详解;3、线性表:链表详解;4、队列,栈,Hash表详解;5、树详解(平衡树,B树等);6、堆详解(大根堆,小根堆);7、图详解;8、跳表,布隆过滤器等; -
经典算法
经典算法
1、算法的概念和表示方式;2、算法的复杂度衡量(空间和时间);3、递推、递归、穷举、迭代、分治;4、贪心、动态规划、分治限界;5、查找算法、加密算法;6、压缩算法、图相关算法;7、一致性Hash算法;8、分布式一致性算法; -
J V M详解和调优
JVM详解和调优
1、JVM组织架构;2、JVM内存结构;3、JVM各内存区域的概念和作用详解;4、JVM类加载器和自定义类加载器;5、JVM垃圾回收算法;6、JVM垃圾回收器;7、JVM各种参数详解;8、JVM常用调试工具使用总结; -
P y t h o n 和爬虫
Python和爬虫
1、Python编程语言概述;2、Python基础语法;3、Python的集合和函数;4、Python的文件读写;5、爬虫的概念、作用和工作机制;6、第一个爬虫程序;7、requests,beautifulsoup,xpath详细使用;8、scrapy实现爬取拉勾/知乎项目; -
H a d o o p调优
Hadoop调优
1、版本调优;2、压缩调优;3、文件格式调优;4、参数调优;5、操作系统调优;6、代码调优;7、资源调优;8、架构调优; -
S p a r k内核设计
Spark内核设计和源码阅读
1、SparkContext对象的初始化详解;2、DAGScheduler的初始化和工作职责详解;3、TaskScheduler的初始化和工作职责详解;4、Master角色的启动和工作职责详解;5、Worker角色的启动和工作职责详解;6、Spark应用程序的Stage划分详解;7、Spark应用程序的并行度计算详解;8、Spark任务执行流程的源码解读; -
S p a r k G r a g h X
Spark GraghX
1、图基本概念介绍;2、图的属性;3、图数据存储;4、图数据库介绍;5、入口案例演示;6、GraghX核心API详解;7、图计算案例演示;8、社交网络潜在好友推荐; -
S p a r k M L
l
i bSpark MLlib
1、SparkMLlib向量介绍;2、矩阵介绍和常用计算;3、Pipline机器学习流;4、数据的标准化,正则化,缺失值处理;5、L1,L2正则化;6、PCA主成分析、朴素贝叶斯;7、随机森林、逻辑回归;8、推荐系统; -
E S存储机制
ElasticSearch存储机制
1、ES分布式架构、扩容和容错;2、分片&副本分配机制;3、document的核心元数据详解;4、document数据路由原理;5、文档的全量替换;6、ES的延迟删除机制;