

光环大数据学员就业薪资一览


大数据工程师

数据挖掘工程师

hadoop开发工程师

大数据开发工程师
工作经验:曾就职于新浪微博平台研发部与Hulu北京研发中心,曾参与微博核心Feed系统的改造,主导多机房数据同步和容灾部署,Spark内核级优化和企业推广,Hadoop集群升级与优化,Hive On Tez优化以及推广等工作。曾在某在线视频公司及新浪等大型企业大数据培训担任讲师。

工作经验:8年+大数据研发经验,美国著名视频公司大数据架构师,曾在中国云计算大会、世界软件大会、中国架构师大会等担任演讲嘉宾。在中国福彩、中国银行和工商银行、国家电网等国家级项目中担任大数据内训讲师。编写大数据Hadoop技术书籍,畅销十万余本。

工作经验:目前就职于美国某著名在线视频公司,从事Hadoop及Spark相关平台的研发工作。曾参与维护并优化千节点规模的Hadoop集群,对分布式存储系统有深入研究(源码级修改),尤其擅长HDFS/HBase调优及应用:利用impala与presto大数据查引擎构建企业级OLAP引擎,对高性能查询优化有丰富经验。

工作经验:曾任百度大数据负责人,中国银联分布式技术专家,Oracle甲骨文高级工程师。专业聚焦流式处理、数据平台构建、互联网数据产品研发等。在商用版Storm、国内顶级数据平台、以及百PB量级数据治理等项目中,担任设计、研发及落地leader。曾受邀在国内顶级大学做大数据主题分享,工作成果在知名专业书籍上多有论及。













学习阶段概述:大数据技术体系、Hadoop生态系统,具体涉及HDFS/YARN/HBase/Kafka/Hive/Presto等架构、实际应用情况。
学习阶段概述:Spark技术概论、Spark生态系统组成、相关组件的原理以及程序设计的方法、调优,典型大数据分析案例剖析
深度学习背景及发展史,常见应用(自动驾驶、机器翻译、人脸识别等)、常见Python机器学习库、深度学习算法及开源库Tensorflow介绍
本章通过讲解综合的项目案例,完整的展示大数据在实际应用场景中复杂应用情况,让学员掌握
学员以小组的形式配合完成结业项目,并进行答辩,由讲师、班级同学共同进行评审
课程一阶段
学习目标:
掌握Java流程控制和数组、面向对象、集合框架、异常和泛型和注解、IO流、并发编程等知识。完成项目:
Java多线程模拟多窗口售票,Java集合框架管理。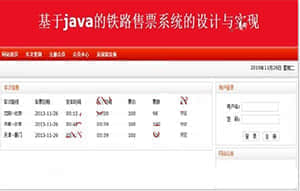
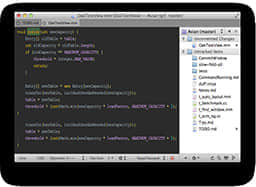
第一阶段主要内容:
初识Java
流程控制与数组
面向对象及方法重载
并发编程
课程二阶段
学习目标:
掌握数据库MySQL和SQL、Maven、Git/SVN、MyBatis/Hibernate、Spring、SSM整合。完成项目:
京东电商网站项目、2048游戏项目、智能图书管理系统。
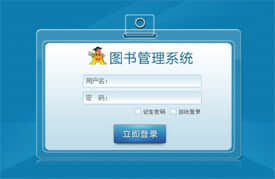
第二阶段主要内容:
数据库MySQL和SQL
Maven、Git/SVN
MyBatis/Hibernate
Spring
课程三阶段
学习目标:
掌握VMWare虚拟机安装和使用、Linux文件系统、Linux文本编辑命令Vim、Linux网络管理等。完成项目:
公司网络拓扑实战、构建企业网站和邮件应用平台、构建服务器管理监控系统。
第三阶段主要内容:
VMWare虚拟机安装和使用
Linux文件系统
Linux文本编辑命令Vim
Linux网络管理
课程四阶段
学习目标:
掌握集合和排序、反射和设计模式、并发编程/多线程、数据结构、经典算法、JVM详解和调优。完成项目:
类QQ聊天室、RPC模拟实现。
第四阶段主要内容:
集合和排序
反射和设计模式
并发编程/多线程
数据结构
课程五阶段
学习目标:
掌握Common和RPC、HDFS分布式文件系统、MapReduce分布式编程模型、YARN资源调度系统等。完成项目:
微博数据大数据分析项目、用户行为分析项目、精准广告投放项目。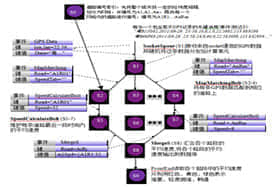
第五阶段主要内容:
HDFS分布式文件系统
MapReduce编程模型
YARN资源调度系统
ZooKeeper协调服务
课程六阶段
学习目标:
能够熟练使用Flume分布式数据采集工具、Kafka分布式消息系统、Storm分布式流式计算引擎等。完成项目:
实时处理新数据和更新数据库,处理密集查询并行搜索处理大集合的数据。
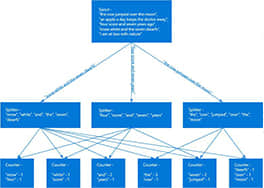
第六阶段主要内容:
Flume分布式数据采集
Kafka分布式消息系统
Storm流式计算引擎
HBase分布式数据库
课程七阶段
学习目标:
掌握Scala编程语言基础语法、Scala面向对象、Scala函数式编程、Scala的并发编程和Spark的RPC。完成项目:
记录用户行为、统计页面转化率,热门商品及黑名单统计
第七阶段主要内容:
Scala编程语言基础语法
Scala面向对象
Scala函数式编程
Scala的并发编程
课程八阶段
学习目标:
熟练使用Spark、Spark Core、Spark内核设计和源码阅读、Spark SQL等进行快速开发。完成项目:
使用Spark处理离线数据、使用SparkStreaming完成实时计算。

第八阶段主要内容:
Spark编程开发
Spark Core
Spark SQL
Spark Streaming
课程九阶段
学习目标:
能够掌握ElasticSearch核心概念、安装部署、查询和分析、存储机制等能力。完成项目:
实时索引存储节点,elasticsearch建立索引精准搜索分析。

第九阶段主要内容:
ElasticSearch核心概念
ElasticSearch安装部署
ElasticSearch查询和分析
ElasticSearch存储机制
课程十阶段
学习目标:
熟练Flink简介、Flink架构和集群安装、Flink应用案例、Flink原理分析。完成项目:
Kafka对接Flink的消费数据展示及整合、高吞吐。

第十阶段主要内容:
Flink简介
Flink架构和集群安装
Flink应用案例
Flink原理分析
课程十一阶段
学习目标:
熟练模型评估与选择,熟练使用机器学习各种算法,掌握机器学习与大数据的结合。完成项目:
广告CTR预估及投放,智能数据实时监测项目社交图谱大数据分析。

第十一阶段主要内容:
Python工具库实战
机器学习基础理论概述
机器学习入门
机器学习进阶
课程十二阶段
学习目标:
能够熟练进行版本调优、压缩调优、文件调优、参数调优等八大集群调优。完成项目:
大数据并发超大集群调优,服务器大集群架构调优,超大数据资源调优。

第十二阶段主要内容:
名企合作 就业双选 做教育我们是认真的
我们的学员值得更好的选择








阿里云栖大会,光环与阿里云形成战略合作

光环大数据与腾讯云深度合作签约仪式

华为2016全球合作伙伴大会与光环达成战略合作


融合阿里项目为你的技术镀金

光环大数据与阿里战略发布会

光环董事长合作发布会致辞

阿里云大学副总阐述光环大数据

阿里云大学宁院长心对光环评价
点击任意处关闭
点击任意处关闭
点击任意处关闭
点击任意处关闭

有位老师想和您聊一聊





