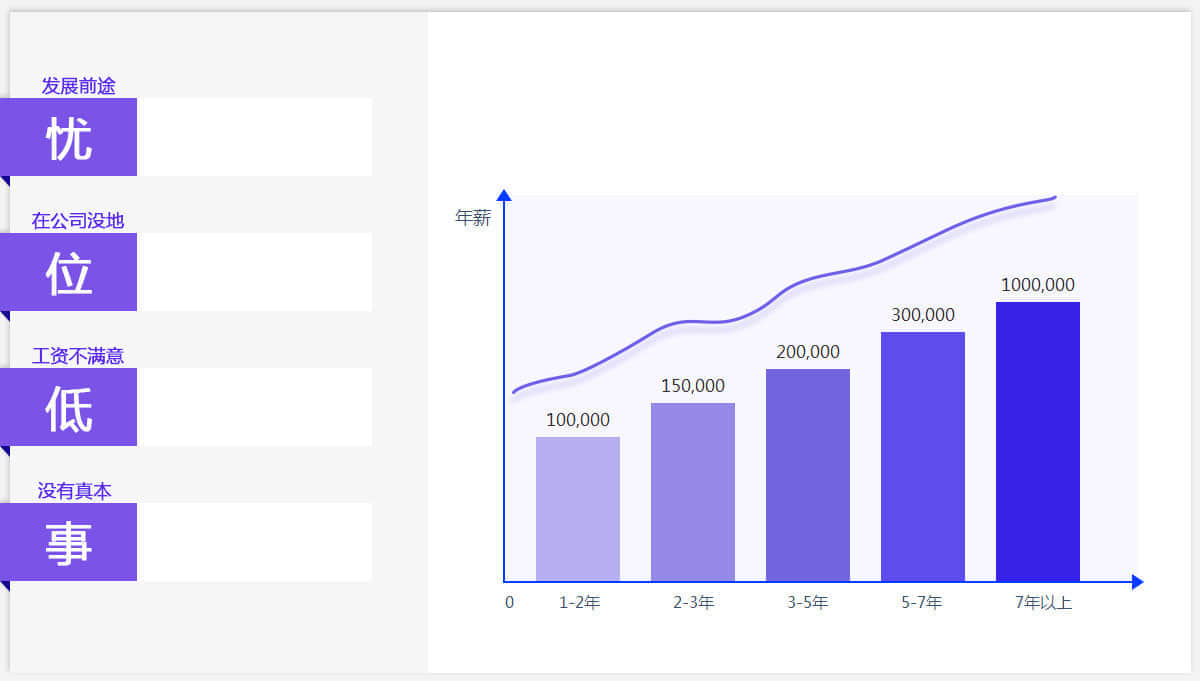
15
年
16
年
17
年
18
年